Keep Innovating! Blog

えーっ、最強の乱数シードがあるんですか!?
目次

皆さんこんにちは! 技術創発推進室の高岡です。
あけましておめでとうございます。本年もどうぞよろしくおねがいします。
さて、新年一発目ということで、去年読んだ中で一番”奇妙”なタイトルの論文をひとつご紹介しようかと思います。これは社内の人(というか、中西なんですが)から教えてもらったものです。もうそのタイトルからしてなかなかに挑戦的なんですよ。
ええ、ここ数年、”Attention is all you need” を皮切りに、 ”... is all you need” 論文はよく目にしましたよね。
でも。でもですよ。「Torch の乱数シード 3407 だけあればいい!」だって? まさか! そんなことが...... いや、でも論文にするくらいだし、全くの与太ってこともないだろう...... なんだこの...... 何? 全然想像がつきません。
こうなりゃ、読んでみましょう。するとわかるはずです。乱数シード 3407 とは、一体なんなんでしょう?
例によって、今回の記事内の図表は上掲の論文から引用したものです。
研究の動機
まずは、動機から確かめていきましょう。
この論文の著者は、乱数が(コンピュータビジョン分野の)機械学習に与える影響に関心を持ちました。具体的には、こんなことです。
- 乱数シードを変えることで、性能はどのくらいバラつくのだろう?
- 大ハズレ(原文では black swan)はあるか? 結果に大きな影響を与えるシードはあるのだろうか?
- 大きなデータセットで事前学習しておけば、シードの影響を緩和できるだろうか?
モデルもデータもどんどん巨大なものを使うようになった昨今、一回だけ実験した結果でもって判断するのは、危険がありそうです。計算機資源がとても貴重なら、実験回数ゼロ回よりは1回でもあるほうがずっとマシではあるわけですが、そうはいっても統計的な検証もなしに、ただ一度の実験の結果を信じてよいか? と言われると、ちょっと不安ですね。
このあたりの話は、前回の私の記事でも「早合点病」として扱いました。この論文の著者も物理学の話を引き合いに出して、実験と再現のプロセスに触れています。
さて、もし、どんなシードを選んでも訓練の結果が大して変わらないなら、シードの影響は無視してもよいのでしょう。でも、そうでなかったら? そのときには、機械学習の実験でも、乱数の影響というものを精査する必要性がある、ということです。
というわけで、乱数シードの影響を調べてみましょう!
実験条件
乱数シードの影響が見たいなら、いろんなシードについてそれぞれモデルを訓練して、性能の分布や傾向をみたらよさそうですね。
そこで、著者が実施した実験は、こうです(実験のナンバリングは筆者による)。
- 実験a:
- 実験a-1:
- CIFAR10 をデータセットに、
- ResNet っぽい 9 層のネットワークのモデルを、
- 10000シードにわたって訓練・評価する
- 各シードにつき、30秒だけ訓練する。
- 実験a-2:
- CIFAR10 に対して本当に収束するものか確かめるため、
- 500シード分についてだけ、1分間の訓練をした。
- 実験a-1:
- 実験b:
- ImageNet をデータセットに、
- 既存のモデル(3種)について、出力層だけ fine tuning することにして、
- モデル1 - PyTorch 標準の訓練済み ResNet50
- モデル2 - DINO の SSL (= 自己教師学習) ResNet50
- モデル3 - おなじく DINO の SSL Visual Transformer(ViT)
- 各モデル 50 シードづつ訓練・評価する
ともかく、たくさんのシードについて実験がしたいので、モデルもデータもある程度コンパクトなものがよろしいです。また、この研究は世界最高性能を目指すようなものでありません。そう考えてみれば、モデル自体は「ありもの」を持ってこれば十分です。なにも、新しいものを考えつかなくてもいいんですから。
実験aとbとで扱っているシードの数が大きく違いますが、これは訓練・評価にかかる時間の違いのためです。実験a-1では、1回の訓練と評価につき30秒しかかけませんが、実験bではモデルにより2時間〜3時間40分かかっています。この時間制限は予算的な制約によるものだということです。「もっと長い間訓練すれば、違うことが言えるかもしれない」といった留保事項は論文中に挙げられていました。
著者の発見
著者はこの一連の実験を通じて3つの発見をした、と言っています。順に見ていきましょう。
発見1: シードによる性能のばらつきは小さく、よく集中している
これは、実験a-2(CIFER10 について、500シードに渡って、1分間訓練した)に関するものです。次のグラフを見てください。

まず、左の Figure 1 からです。これは 500 訓練分の学習曲線を示したグラフです。実線がエポック(横軸)における、精度(縦軸)の平均、濃い赤色の部分が標準偏差1の範囲、薄い赤色が最大 & 最小です。
25エポックのあたりでグラフは横ばいになっているので、概ね収束している、ということがわかりますね。収束してから後には、標準偏差もほとんど縮小していない(濃い赤の部分が狭くなっていっていない)、ということも見て取れます。このことからは、「長い間訓練をすることで、性能のばらつきを抑える、という効果は期待できないだろう」と言えそうです。
続いて、右の Figure 2 に移りましょう。これは 500 訓練の最終的な性能の分布を示したものです。横軸は精度で、縦軸が頻度のヒストグラムになっています。
90.5%〜91%のあたりの、わずか0.5%の範囲によく集中した、「尖った」分布になっていますね。
というわけで、この研究の問1「乱数シードを変えることで、性能はどのくらいバラつくのだろう?」についての答えは、こうです。
「シードによる性能のばらつきは小さく、よく集中している」
これは、一安心ですね。
発見2: 極端に良い結果を与えるシードは、確かに存在はする。いいシードが引ければ、性能改善したものと見えてしまう(その逆も然り)。
実験a-1(10000シードについて、それぞれ30秒だけ訓練した) の結果を見てみることにしましょう。次の表をご覧ください。

実験1に関する性能を示したものです。下の「short」が実験1-bに対応します。この行の、「最大の精度」と「最小の精度」の差に注目しましょう。90.83% - 89.01% = 1.82% の開きがあります。この差は、研究コミュニティにとって、意味のある差としてみなされる程度の差であるということです。
分布は次のヒストグラムに示すとおりでした。
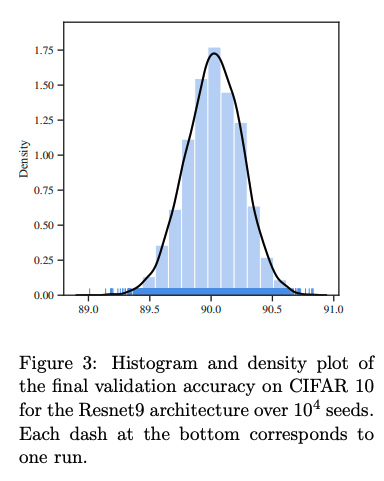
これも、よく尖っている、とはいえそうです。10000のシードを調べて得られる、極端に良い性能のものや、極端に悪い性能のものは、このモデルの代表的な性能である、とは言いにくいようですね。言い換えれば、珍しくはあるものの、代表的でない、といえるほど良い(または悪い)性能をもたらすシードがあり得る、ということでもあります。
というわけで、ここから二番目の問い「大ハズレ(原文では black swan)はあるか? 結果に大きな影響を与えるシードはあるのだろうか?」に対する答えは、こうです。
「極端に良い(または、悪い)結果を与えるシードは、確かに存在はする。いいシードが引ければ、性能改善したものと見えてしまう(または、その逆)。」
性能偏重主義には、注意が必要でしょう。運良く”当たり”のシードを引いただけかも知れませんからね。
発見3: 大きな訓練セットとファインチューニングは、シードによる性能のばらつきを抑えるが、ばらつきの範囲内でも、性能が変化したように見えることがある
次に、実験b(ImageNetデータをつかって、既存モデルをファインチューニングした)についてのお話です。
実験b の各モデルについての性能を表で示します。

各行は、上から順に「Torch の ResNet」「自己教師学習で事前訓練された ResNet」「自己教師学習で事前訓練された Visual Transformer」を示しています。
各モデルについて、性能の振れ幅をみると、最大と最小の差はおよそ 0.5% 程度、と先のCIFAR10の実験よりも狭くなっています。ところが、この 0.5% というのは、ImageNet について言えば「意味のある差である」と考えられるものなのです。
次に性能の分布を示します。
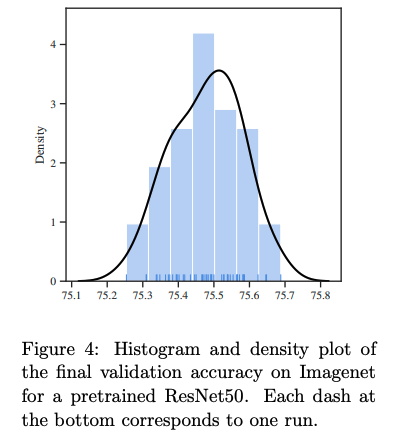

著者はこれを見て、「もっと多くのシードについて検証したなら、そのときにも性能の開きが 1% を超えないだろう、という自信は持てない」という旨のことを書いています。
ここから、この研究の第三の問いに対する答えは、こうです。
「ある意味では、大きな訓練セットと事前学習したモデルからファインチューニングすることは、シードによる性能のばらつきを抑えはする。だが、それでもなお、抑えられたばらつきの範囲内で、性能が変化したように見えることがある」
たった50個のシードを調べただけで「意味のある差」が得られてしまうなら、昨今の研究報告についても、過大評価されているのでは? という気もしないでもないです。
最強のシード 3407 の正体
これは、論文にははっきり書いてあったわけではないのですが、まあここまできたら明らかですね。「当たり」のシードのことでしょう。大当たりのシードでは、大ハズレのシードよりも良い性能(に見える結果)が出てしまう、ということだったんでした。
どう考えても、当たりのシードを引くことは、良いモデルをつくったことにはなりませんよね。そういうランダム性の影響を差っ引いた結果、というのが知りたいものです。
著者は論文の結びに、「機械学習モデルについて論文化するときには、シードを変えながらモデルの性能を調べて、平均・標準偏差・最良・最悪について報告すべきでは? 」という提言をしています。
まとめ - 我々はどうすべきか?
シードの影響って、ちょっと無視できないくらいにはあるんですね。この結果は、なかなか衝撃的でした。
著者はさらに背筋の凍るようなことを書いています。
- 機械学習の研究って、ハイパラやモデルの構造を調整しながら訓練を繰り返すよね。
- そのなかで、一番良かったモデルについて論文化するよね。
- それ、意図せず、シード探索しちゃってるんじゃない?
うわーっ、そう考えると結構恐ろしいものがあります。
たとえば、試行錯誤の果てに、良い性能の出るモデルができました、としましょう。そのネットワークの構造を使って、訓練データを時々取り替えながら、モデルの調整をすると...... なぜか性能が落ちる。実は最初にモデル作ったときのシードが大当たりだっただけでした、ということがありうる、と。これはそういうお話ですね。怖いですね。怪談は夏だけにしてほしいですが、これには妖怪も幽霊も関係なくて、ただのランダム性の問題だというのがまた怖い。
モデル開発をするときにも、たまたま良い性能だったんじゃないの? という疑問を排除しておく必要がありそうですね。良さそうなモデルが得られたら、しばらく繰り返しランダムなシードで評価をする、というステップを挟むのが重要そうです。そうしておけば、モデルを過大評価することも、過小評価することもなく、きちんと見ることができるでしょう。
著者プロフィール
名前: 高岡陽太
株式会社オープンストリーム/技術創発推進室
長らく Web 系のシステム開発をしてきたが、2019年頃から機械学習関連の案件に携わり始めた。
ディープラーニングモデルの開発からその API 化、フロントエンド開発まで、必要とあらば一通り手掛ける。
最近は、機械学習それ自体はもとより、機械学習開発を支える技術としての MLOps に興味を持っている。
MLOps 用基盤ツール Knitfab の開発リード。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps