Keep Innovating! Blog

[Knitfab 技術ハイライト] 機械学習タスクを過不足なく自動実行する技術 -- #2 Nomination: “使える Data” はどれなんだ
はじめに
みなさんこんにちは。株式会社オープンストリーム・技術創発推進室、Knitfabチーフプログラマの高岡です。
この記事は Knitfab の主要機能のひとつである「自動ワークフロー」について、その詳細に迫る連載記事の 2 回目です。
- #1 自動ワークフローのオーバービュー (前回)
- #2 Nomination: “使える Data” はどれなんだ(今回)
- #3 Projection: “足りない Run” を見つけ出す
まだ 1 回目の記事をお読みいただいていない読者には、この先を読み進める前に、そちらに先に目を通していただくことをおすすめします。
1回目では、Knitfab が機械学習タスクの記録である Run を生成する流れの、大まかな部分について説明しました。今回は、2 つある大きなステップ Nomination と Projection のひとつめにあたる Nomination について深堀りしてゆきます。
Nomination: Data と入力を対応付ける
まずは前回のおさらいから。Knitfab は、Run の雛形にあたる Plan の入力に Data がアサイン可能かどうか、ということを Tag を使って判定しています。
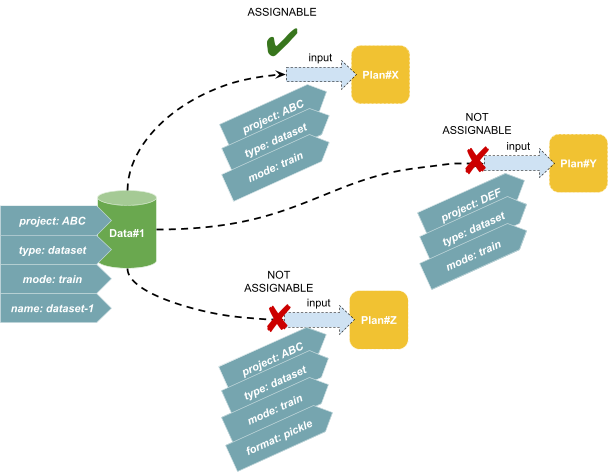
アサイン可能性の判定規則は「Plan の入力についている全ての Tag が Data にもついているなら、その Data は入力にアサイン可能」というものです。Knitfab は、この規則で決まる「入力とアサイン可能な Data 」の組、すなわちアサイン候補の一覧を管理しているのでした。
この「アサイン候補の一覧」を管理しているのが Nomination というステップです。Data の Tag が追加・削除されたときや Data そのものが追加・削除されたとき、あるいは Plan が新しく登録されたとき、その都度この一覧を更新して、実態に合わせているのです。Nominationという呼び名は、入力に対して Data を”ノミネート/Nominate”して、アサイン候補にする、というニュアンスです。
上記の仕様に従って Nomination を成立させるためには、入力と Data の間の Tag の関係を調べる必要がありますね。数学の集合の記号を使って「Data の Tag」 ⊇ 「入力 の Tag」という関係(包含関係)になっている組み合わせは、アサイン候補だ、と言えます。
ところで、 Knitfab ではデータベースとして RDB (PostgresSQL) を採用しています。Tag や、Data 、 Plan やその入力・出力に関する管理情報は、それぞれ独立したテーブルが定義されていて、外部キー制約をつかって整合性をとっています。
これらのテーブルと制約のうち、アサイン可能性判定に関する部分を一部抜き出せば、およそ図1のようになります。

四角く囲まれているのがテーブル名です。矢印は外部キー制約の参照の向きです。
Tag (“tag” テーブル) と Data(”data” テーブル)が中間テーブル “tag_data” を挟んで多対多対応しています。また Tag と入力(”input” テーブル)も同様に “tag_input” を挟んで多対多対応しています。要するに「Data にはたくさん Tag がついていてよいし、ある Tag が複数の Data についていてよい」という仕様を、制約を使って表現しています。さらに、アサイン候補リストは “nomination” テーブルに記録されていて、アサイン候補の Data・入力組を保持するように定義されています。SQL 的には、Nomimnation とは、”nomination” テーブルに適宜 insert したり delete したりすることだ、ということですね。
さて、問題はここからです。Data についている Tag群 は “tag_data” を調べるとわかります。また、入力についている Tag群 は “tag_input” を調べるとわかります。では、ある Data の Tag群 が、どの入力の Tag群 を全て含んでいるか、をSQLで調べるには、どうしたらいいでしょうか? Tag群同士の「共通部分はなにか」なら簡単です(inner join をとれば見つかります)が、「含む/含まれている」となるとちょっと工夫が必要でした。
Knitfab では、次の発想に基づくアルゴリズムを採用しています。
ある Data の Tag が更新されたあと、Knitfab に登録されている各入力に対して
- 入力の Tag の個数を数える
- その入力と更新対象の Data との間で共通している Tag の個数を数える
- 1. と 2. が同じ個数になったときだけ、Data はその入力にアサインできる
文字だけはちょっとわかりにくいですね。図にしましょう。
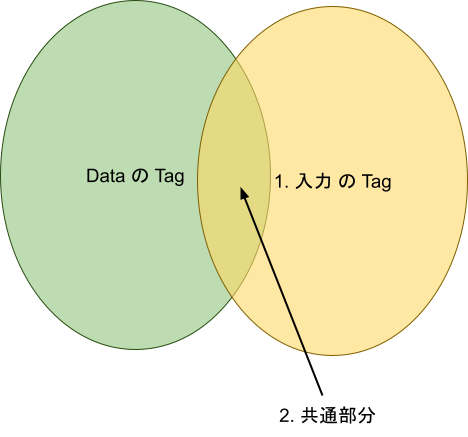
図2では、Data の Tag と入力の Tag、および共通部分の関係を示しています。この図は、Data についている Tag (左側の緑の領域)と、入力についているTag (右側の黄色い領域)があって、その一部が重なっている、つまり共通部分があることを示しています。このような状態だと、Data の Tag のなかに入力の Tag が全部含まれているわけではないので、アサイン不可能です。では、アサイン可能な状態では、共通部分はどうなるでしょう? それは図3のとおりです。
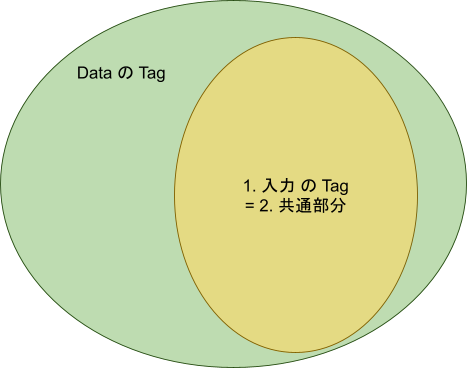
入力の Tag が完全に Data の Tag に含まれているのですから、入力の Tag は共通部分と完全に一致するはずですね。ということは、入力の Tag 個数(1.)と、共通部分の Tag の個数(2.)を数えて、個数が同じになれば(3.)、「Data の Tag は入力の Tag を含んでいる」と言える、というわけです。
「個数を数える」の SQL 的な表現は、当然 count ですね。また「共通部分」は ”tag_data” inner join “tag_input” using (“tag_id”) で得ることができます。
…..というわけで、この基本的な考え方に基づいて SQL を書けば、
with "cardinality_i_tags" as ( -- 1. 入力の Tag の個数を数える
select
"input_id", count(*) as "c"
from "tag_input"
group by "input_id"
),
"cardinality_i_and_d_tags" as ( -- 2. 入力と Data とで共有している Tag の個数を数える
select
"input_id", "knit_id", count(*) as "c"
from "tag_input"
inner join "tag_data" using("tag_id")
group by "input_id", "knit_id"
)
select
"input_id", "knit_id"
from "cardinality_i_tags"
inner join "cardinality_i_and_d_tags" using ("input_id", "c") -- 3. 個数が同じになったときだけ、Data は入力にアサインできる……といった感じになります。 with 句 cardinality_i_and_d_tagsで行っている inner joinが 「Tag を突き合わせて共通部分を探す」という操作に対応しています。末尾にあるクエリ本体では、入力ごとの Tag 個数(cardinality_i_tags )と共通部分の Tag 個数 (cardinality_i_and_d_tags)が同じになった入力と Data の組み合わせを取り出しています。これで、クエリ一発で Nomination で求めたい一覧が得られます。
効率化
さて、これで一応 Nomination できるようになりましたが、毎回一覧表を全部作り直すのはどうにも”やりすぎ”です。Nomination ステップを開始するきっかけは Data や Plan の変化に他なりません。ですから、そのきっかけになった Data や Plan に関係するアサイン候補だけ更新してやれば、差分更新ができるはずです。
差分だけを対象とするということは、SQL 的には、更新された Data や Plan に関係のないレコードをクエリの探索範囲から外すということです。たとえば、Data の Tag が更新されたことをきっかけに Nominaton を開始したなら、新しいアサイン候補を探す範囲は「全Data × 全入力」ではなくて「更新された特定のData × 全入力」で十分であるはずだ、ということですね。更新されなかった Data に関係するアサイン候補には変化がないはずなので、その範囲を探すのは無駄です。
この場合には、 cardinality_i_and_d_tags を求めるにあたって、”tag_data” テーブルのうち更新された部分集合だけを join することで、探索範囲を抑えています。次のようにします。
with
"data" as (
select "knit_id" from "data"
inner join "run" using("run_id")
where "knit_id" = $1 and "status" = 'done' -- *. 更新された Data の ID ($1) について絞り込んでおく。念の為上流 Run が完了していることを確認する
),
"d_tags" as ( -- *. "tag_data" から、更新された Data に関する部分だけを取り出す
select
"knit_id", "tag_id"
from "tag_data"
inner join "data" using("knit_id")
),
"cardinality_i_tags" as ( -- 1. 入力の Tag の個数を数える
select
"input_id", count(*) as "c"
from "tag_input"
group by "input_id"
),
"cardinality_i_and_d_tags" as ( -- 2. 入力と Data とで共有している Tag の個数を数える
select
"input_id", "knit_id", count(*) as "c"
from "tag_input"
inner join "d_Tags" using("tag_id")
group by "input_id", "knit_id"
)
select
"input_id", "knit_id"
from "cardinality_i_tags"
inner join "cardinality_i_and_d_tags" using ("input_id", "c") -- 3. 個数が同じになったときだけ、Data は入力にアサインできる
これで、 cardinality_i_and_d_tags を求める際に join すべき行数を削減できます。元々全入力の全タグ×全Dataの全タグ(”tag_input” inner join “tag_data”) を考えていたところ、全入力の全タグ×特定Dataの全タグ("tag_input" inner join "d_tags")を考えれば済むようになりました。こうして導かれたアサイン候補を ”nomination” テーブルに insert することで、Data の変更に起因する Nomination が実行されています。
Plan が追加されたときの Nomination も似たようにして、”tag_input” を直接扱う代わりに、新規 Plan に関する部分のみに制限することで探索範囲を抑えています。
実際の実装では、もう少し複雑なクエリの中にここで示したようなクエリが埋め込まれているという形をとっています。というのも、Knitfab が予約している特殊な Tag の情報は “tag” テーブルにないことや、Data から Tag が除去されたことでアサイン候補から外れた組を検出して、”nomination” テーブルから削除する必要があるためです。
ともあれ、こうしたテクニックを用いて “Data とそれをアサイン可能な入力の組の一覧” を差分更新できるようになっています。
ここまでのまとめ
Data が入力に対して「アサイン可能」になるまでの流れをご紹介しました。また、「Tag 集合を含むとき」を SQL 的に表現するテクニックについてもご紹介しました。
次回は実際に Run を生成する、すなわち、 Plan の入力に Data をアサインする仕組みを追いかけていきます。お楽しみに!
著者プロフィール
名前: 高岡陽太
株式会社オープンストリーム/技術創発推進室
長らく Web 系のシステム開発をしてきたが、2019年頃から機械学習関連の案件に携わり始めた。
ディープラーニングモデルの開発からその API 化、フロントエンド開発まで、必要とあらば一通り手掛ける。
最近は、機械学習それ自体はもとより、機械学習開発を支える技術としての MLOps に興味を持っている。
MLOps 用基盤ツール Knitfab の開発リード。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps