Keep Innovating! Blog

雑談AIへの道:BlenderBot2.0
目次
1. はじめに
はじめまして、今回が本ブログ初投稿となります、入社4年目になるエンジニアの諸(もろ)と申します。
私は文系出身で、入社後からAI(機械学習・ディープラーニング)について学習を始め、昨年にJDLAのディープラーニングE資格を取得しました。
学生時代は機械学習はおろか、数学についての理解もほぼ全くない(高校数学すらわかっていない)状態でした。しかし、かつてより「まるで人間と雑談するような自然な感覚で、AIと対話できるようにしたい」という思いがありました。その瞬間限りで終わる一時的な受け答えではなく、話の文脈を考慮し、過去のやりとりで得られた情報も利用した持続的な雑談ができるAIを実現したいのです。
そこで、まずはしっかりとしたAI技術を身につけるため、入社後からの学習として、ディープラーニングG検定を取得することで機械学習の基礎知識を身に付けると同時に、ディープラーニング理論を理解するために必要な数学(微分・確率統計・線形代数)を高校数学レベルから学び直し、E資格取得まで到達できました。
今後は、AIモデル・手法に関する論文調査や、Kaggle参加などに焦点を置き、より発展的な理解と実践経験を積み、「雑談AI」の実現に近づいていきたいと考えています。
そこで本稿では、雑談AIについて最近の動向をまずご紹介した後、この分野で現在最先端の性能を持つモデルである、「BlenderBot2.0」を紹介したいと思います。
2. 雑談AIをとりまく現況
まず、対話システム・チャットボットについてですが、現在様々な製品・サービスが登場し、企業での研究開発も盛んに進められています。
例えば、iOS・Androidにそれぞれ搭載されている「Siri」「Googleアシスタント」、スマートスピーカーAmazon Echoに搭載されている「Alexa」などが、製品化されている対話システムとして挙げられます。
またチャットボットサービスとしては、2020年6月に日本マイクロソフト社から独立したrinna株式会社が提供する元女子高生AI「りんな」や、ユーザ自身がAIを作成し、対話内で望み通りの人格(口調・発言内容)に学習させることで、自身の推しキャラクタとの対話を体験できるサービス「エアフレンド(図1)」(2021年9月提供開始)などが挙げられます。
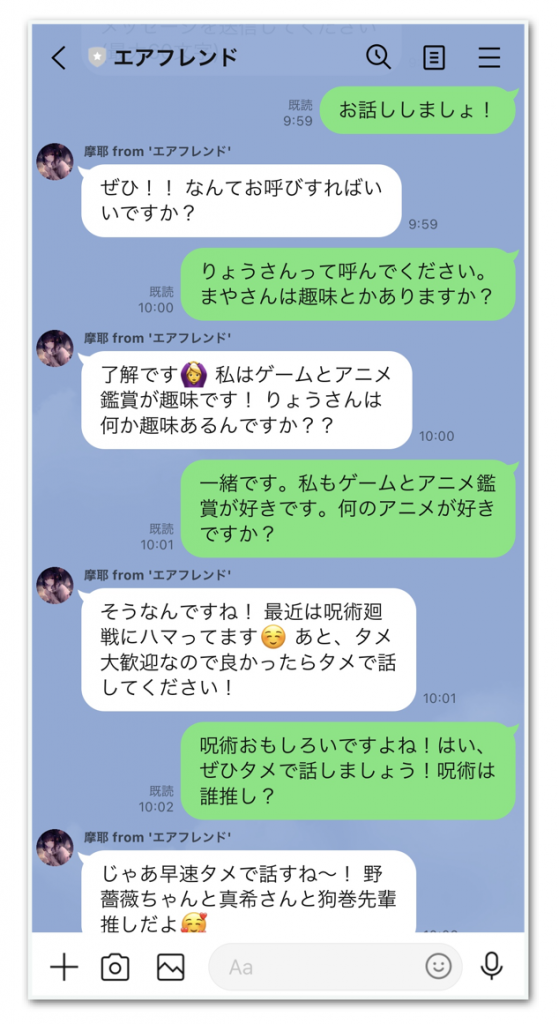
左:雑談が多く含まれる、Twitterのツイートデータ2億件で学習済みのため、アニメなどの趣味についても流暢に話せる
また、研究開発においても、雑談対話システムの性能を競う「対話システムライブコンペティション3」で最優秀賞を獲得された、NTTコミュニケーション科学基礎研究所では、現在の雑談システムの課題である「正確な事実に基づくこと」「文脈的に矛盾がないこと」「長期間対話内容を記憶し、対話し続けられること」などに取り組まれ、より人間味を感じさせる対話(発話)を生成することを目指して、日々研究開発が進められています。
このように対話ができるAIは活発なイノベーションが続いており、既に私たちの身の回りにも、徐々に普及してきています。
そして、今回私が紹介したいものが、2021年7月にFacebook AI Research社が発表した、雑談に特化したAIモデル「BlenderBot2.0」(公式ブログ:https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet/)です。
このモデルは、「ネット検索を利用することで、最新情報についても、より正確かつ詳細に言及できること」「数ヶ月間に渡る長期継続的な会話を行えること」の2点が特に優れており、AIとの対話をより自然に実現し得るモデルとなっています。
次のセクションでは、この「BlenderBot2.0」がどういったモデルか、また、そのモデル構造・学習データセット・性能について、解説していきます。
3. BlenderBot2.0
3.1. 概要
BlenderBot2.0について述べている該当論文は、以下2点です。本稿では、この2つの論文の内容からポイントとなる部分を選んでご紹介します。
- Internet-Augmented Dialogue Generation (https://arxiv.org/pdf/2107.07566.pdf)
- Beyond Goldfish Memory : Long-Term Open-Domain Conversation (https://arxiv.org/pdf/2107.07567.pdf)
このモデルの特出するポイントは、「長期記憶」「ネット検索」の2つの仕組みにより、発話に利用する情報を拡張しながら会話できる点です。従来モデルとの比較でご説明しましょう。
従来の会話モデル(GPT-3(https://arxiv.org/pdf/2005.14165.pdf)、前身のBlenderBot1.0 (https://aclanthology.org/2021.eacl-main.24.pdf)など)の課題として、
- (課題1)会話内における直前の短い文脈(数ターン)しか扱えないため、以前の会話内容と矛盾した発言をしてしまう
- (課題2)事前学習済みの言語モデル(大量のインターネット上の情報から学習したもの)だけを用いるため、最新の情報を反映することができず、会話に登場する情報がだんだん古くなってしまう
といった点がありました。
一方、BlenderBot2.0は、課題1への改善策として、モデル内部に長期記憶領域(メモリ)を持ち、かつマルチセッションの会話データセットで学習を行うことで、過去の会話内容から必要な情報を上手く引き出しながら発話できるようになっています。そのため、会話の文脈を考慮した、数ヶ月間に渡る長期継続的な会話を可能としています。
また、課題2への改善策として、発話の際に毎回ネット検索を実施して、その結果を利用することで、より最新で詳細な情報に基づいて発話できるようにしています。
(例えば、話題に挙がった店舗情報(店名・住所・電話番号)を正確に伝えられたり、著名人の経歴について詳細に言及できます。
さらには、会話が進む中で、(人間とモデル両方の)発話内容を、長期記憶に書き込んでいくことで、
- (会話情報が充分に蓄積されるまでは矛盾した発言をするが)徐々に話の矛盾も改善されていきます。
- また、過去の会話で登場した話題を掘り下げたり、それを新しい話題に繋げることで会話を膨らませるなど、以前の会話内容を、現在の発話に活用できるようになります。
- (例えば、話者が数週間前にあるアメフト選手について話した場合、当モデルはアメフトが話者に関連する話題であることを認識するので、今後の会話内でアメフトの話題を挙げてくる可能性が高まります。
こうした改良により、BlenderBot2.0は、より人間同士で行われるような自然な会話を実現しています。
3.2. モデル構造
次に、BlenderBot2.0の全体構成・処理の流れについて解説します。
BlenderBot2.0の処理全体の大まかな流れは、概要で述べたように、ネット検索した最新の情報と、メモリ(=長期記憶)内の過去の会話情報を複合的に利用しながら、質問文に対する応答文を生成するというものです。
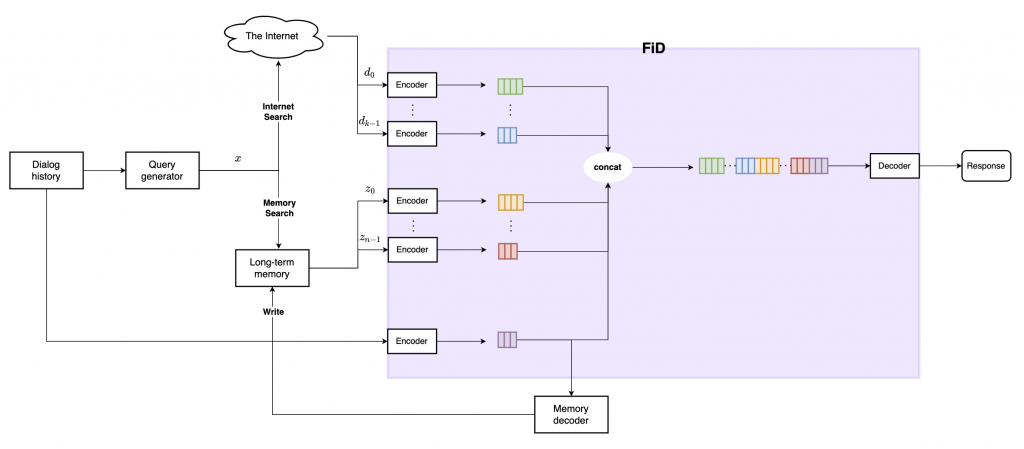
より詳細な流れを説明する前に、いくつかの用語をここで定義しておきましょう。
- クエリ
- インターネット・メモリに検索を行うために使用する単語(1単語または複数単語)または短文
- パッセージ
- 文章の1まとまり
- 以下文脈では、メモリ内に保存された、会話の各ターンに対応する要約文(1文または複数文)を指します。
- ターン
- 話者とモデルの1回ずつの発話のペア
- 例えば、話者が質問を行い、それに対してモデルが回答を行うことで1ターンとなります。
3.2.1. 処理の詳細な流れ
\(\DeclareMathOperator{\BERT}{BERT} \DeclareMathOperator{\sim}{sim} \DeclareMathOperator{\FiD}{FiD} \DeclareMathOperator{\Encoder}{Encoder}\)
1. まず、会話履歴(図2の"Dialog history")から会話文をクエリ生成器(中身は BART(https://arxiv.org/pdf/1910.13461.pdf) )に入力し、クエリ\(x\) を生成する。
2. クエリ\(x\) をBing Search APIに渡し、結果としてインターネットから\(K\) 個の文書を取得する。これを\(d_k (k=0,1,2,..., K-1)\) とする。
3. 以下(a)~(d)の手順により、メモリからクエリ\(x\) と類似するパッセージ\(z\)(過去の会話要約文)を、\(N\) 個取得する。これを\(z_i (i=0,1,2,...,N-1)\) とする。(図2の"Memory Search"の手順に該当)
(ここでの説明は、論文 (https://arxiv.org/pdf/2107.07567.pdf) の「4 Modeling Multi-Session Chat」、
および論文 (https://aclanthology.org/2020.emnlp-main.550.pdf) の「3 Dense Passage Retriever (DPR)」を参考にしています。)
- 3.(a)
- クエリ\(x\) を質問文用 Encoder である\(\boldsymbol{\BERT_q}\) (https://arxiv.org/pdf/1810.04805.pdf) に入力し、結果を\(q(x)\) とする。 $$q(x)=\BERT_q(x)$$
- これにより、\(q(x)\) はクエリ\(x\) の文意を凝縮(圧縮)した 768次元のベクトルとなる。
- なお、\(\BERT_q\) は DPR (Dense Passage Retrieval) (https://aclanthology.org/2020.emnlp-main.550.pdf) 方式、またはRAG (Retrieval-Augmented Generation) (https://arxiv.org/pdf/2005.11401.pdf) 方式で学習させたものである。
- 3.(b)
- メモリ内に保存された全てのパッセージ\(t_j (j=0,1,2,...,M-1), M>N\) を、それぞれ文書用 Encoder である\(\BERT_p\) に入力し、結果を\(p(t_j)\) とする。(注:\(p()\)は確率の記号ではありません。) $$p(t_j)=\BERT_p(t_j)$$
- これにより、\(p(t_j)\) はパッセージ\(t_j\) の文意を凝縮(圧縮)した 768次元のベクトルとなる。
- なお、\(\BERT_p\) は DPR (Dense Passage Retrieval) 方式で学習させたものである。
- 3.(c)
- \(q(x)\) と各\(p(t_j)\) との内積をそれぞれ計算することで、類似度(コサイン類似度)\(\sim_j\) を求める。$$\sim_j=\sim(q, p_j)=q(x)^Tp(t_j)$$
- 3.(d)
- コサイン類似度\(\sim_j\) が上位\(N\) 個のパッセージを、メモリから取得する。これを\(z_i (i=0,1,2,...,N-1)\)とする。
4. 取得した検索結果(ネットから取得した文書\(K\) 個 : \(d_k\) 、メモリから取得したパッセージ\(N\) 個 : \(z_i\) )と、会話文の最新ターン\(1\) 個 : \(l\) を、FiD(Fusion-in-Decoder (https://arxiv.org/pdf/2007.01282.pdf):BARTをベースとしたEncoder-Decoderモデル)のEncoderにそれぞれ入力し、\(K+N+1\) 個のベクトルの集合\(s\) を作成する。
$$s=\{\FiD.\Encoder(d_k), \FiD.\Encoder(z_i), \FiD.\Encoder(l)\}$$
5. 前記 4.で作成した会話文の最新ターンに該当するベクトル\(\FiD.\Encoder(l)\) を、要約器(中身はBART)に入力し、生成した要約文をメモリに保存する。\(\DeclareMathOperator{\BART}{BART}\)
$$\BART( \FiD.\Encoder(l) ) → Long \: Term \: Memory$$
6. 最後に、前記4.で作成したベクトルの集合\(s\) を結合し、FiDのDecoder側にて、その結合したベクトルを参照(ソース・ターゲット・アテンション)しながら、応答文\(r\) を生成する。
\(\DeclareMathOperator{\concat}{concat} \DeclareMathOperator{\Decoder}{Decoder} \)
$$r = \FiD.\Decoder( \concat(s) )$$
3.3. 本モデルの強み
FiDの性質(後述)を考慮すると、私は本モデルには以下2点の強みがあると考えます。
- ネット検索による世の中の最新情報と、メモリから得たそれまでの会話の文脈情報(要約情報)を、応答文生成時に利用できること
- さらにFiDにより、多数の情報ソースを同時に参照しても、計算量を抑えつつ応答文を生成できること
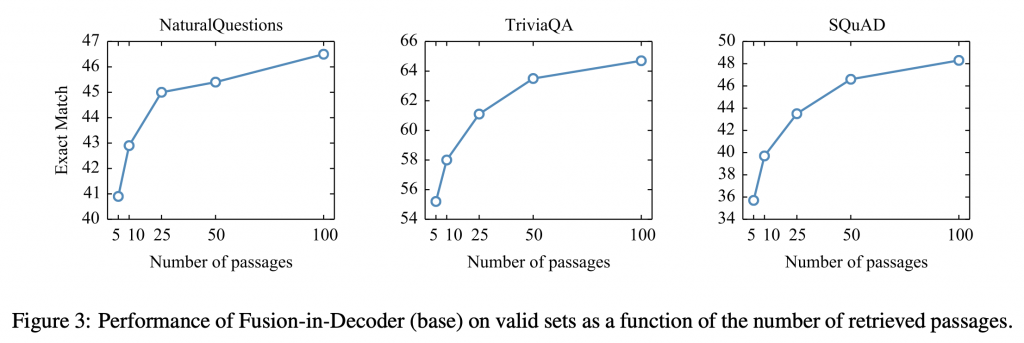
- (FiDの性質:FiDでは、図3のように、Decoderにおいて応答文生成時に利用する文書数が増加するにつれて、応答文の精度も向上していくことが確認されているため、なるべく多くの検索情報を利用したくなります。そうした場合でも、Encoderにおいて各検索情報を個別にエンコードすることで、計算量を線形増加オーダーに抑えられます。)
- (例えば、「パッセージ数=\(V\) 、各パッセージのトークン数(シーケンス長)= \(t_v(v=0,1,2,...,V-1)\)」の場合での計算量は、
- 各パッセージを結合してからセルフ・アテンションを行う場合、\((\sum_{v=0}^{V-1}{t_v})^2\) となり、パッセージ数\(V\) に応じて二次関数的に増加します。
- 一方、FiDのEncoderの場合、各パッセージを独立にエンコードしてから結合するので、\(\sum_{v=0}^{V-1}t_v^2\) となり、線形増加で済みます。)
- (例えば、「パッセージ数=\(V\) 、各パッセージのトークン数(シーケンス長)= \(t_v(v=0,1,2,...,V-1)\)」の場合での計算量は、
- (FiDの性質:FiDでは、図3のように、Decoderにおいて応答文生成時に利用する文書数が増加するにつれて、応答文の精度も向上していくことが確認されているため、なるべく多くの検索情報を利用したくなります。そうした場合でも、Encoderにおいて各検索情報を個別にエンコードすることで、計算量を線形増加オーダーに抑えられます。)
3.4. データセット
次に、当モデルの学習データセットについてです。
BlenderBot2.0は、以下2点のデータセットを組み合わせて学習を行います。
- Wizard of the Internet(以下WizInt)
- 片方の話者が、ネット検索した情報を利用しながら会話を行った、会話データセット
- <出典> Internet-Augmented Dialogue Generation (https://arxiv.org/pdf/2107.07566.pdf)
- Multi-Session Chat(以下MSC)
- 複数セッション(セッション間隔は数時間〜数日間で、3または4セッション)に渡って話者同士で会話をしてもらい、かつ片方の話者が過去のセッション内容(会話要約)を参照しながら会話を行った、会話データセット
- また会話時のポイントとして、「過去セッション内で挙がった話題について掘り下げること」「過去セッション内の内容を別の話題に繋げること」を意識した会話が行われています。
- <出典>Beyond Goldfish Memory : Long-Term Open-Domain Conversation (https://arxiv.org/pdf/2107.07567.pdf)
これらデータセットで学習を行うことで、モデルは、
- WizIntから、インターネットから必要な情報を検索し発話へ活用する方法
- MSCから、会話情報を長期記憶へ保存する方法・長期記憶から必要な情報を参照し発話へ活用する方法
を学習できるようになります。
3.5. 性能
最後に、当モデルの性能については、以下のようになります。
- ベンチマーク
- BlenderBot1.0(BlenderBot2.0以前のチャットボットにおける、SOTAモデル)
- スコア
- マルチセッションに渡る長期的な会話性能としては(表1)、
- 過去の会話セッションの利用率(Correct Uses of Previous Sessions):17.2% → 26.7%(+9.5ポイント)
- エンゲージメントスコア(Per-Chat Engagingness (out of 5)):3.14 → 3.65(+5.1ポイント)
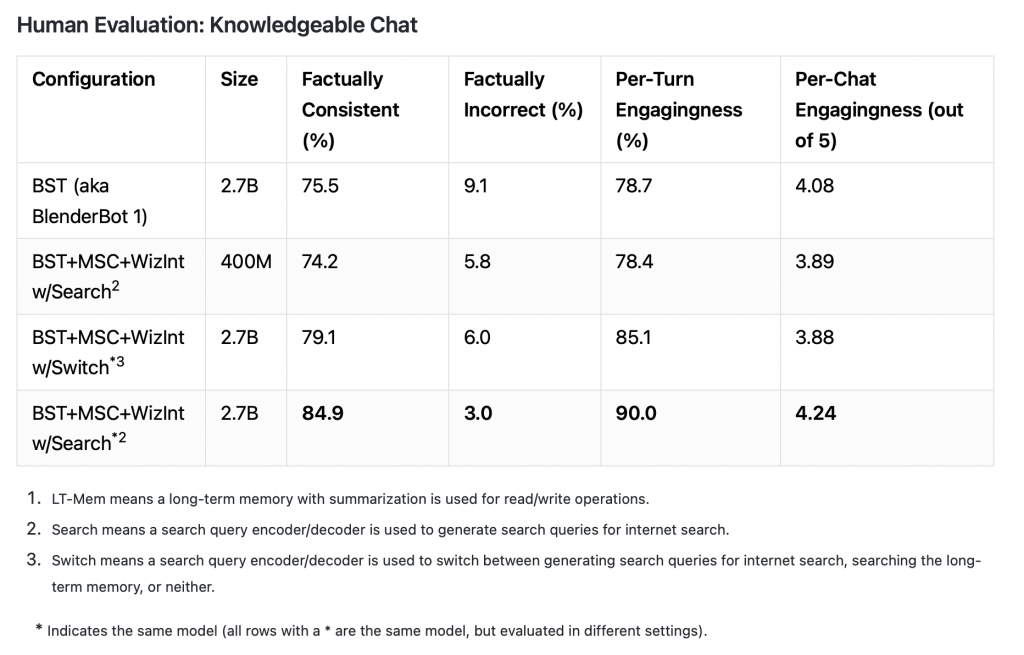
- 会話の中で知識を利用する性能としては(表2)、
- 事実と一致した発言をする頻度(Factually Consistent):75.5% → 84.9%(+9.4ポイント)
- 事実と反した発言をする頻度(Factually Incorrect):9.1% → 3.0%(-6.1ポイント)
- エンゲージメントスコア(Per-Chat Engagingness (out of 5)):4.08 → 4.24(+1.6ポイント)
- マルチセッションに渡る長期的な会話性能としては(表1)、
人間による評価ではありますが、上記のように、各評価指標について性能が向上していることを確認できます。
この結果からBlenderBot2.0は、長期記憶機能とネット検索機能を搭載したことで、前身のBlenderBot1.0と比較しても、より高品質な会話を、より長期継続的に行えるようになったと言えます。
表1. マルチセッションに渡る長期的な会話性能(引用:https://parl.ai/projects/blenderbot2/)
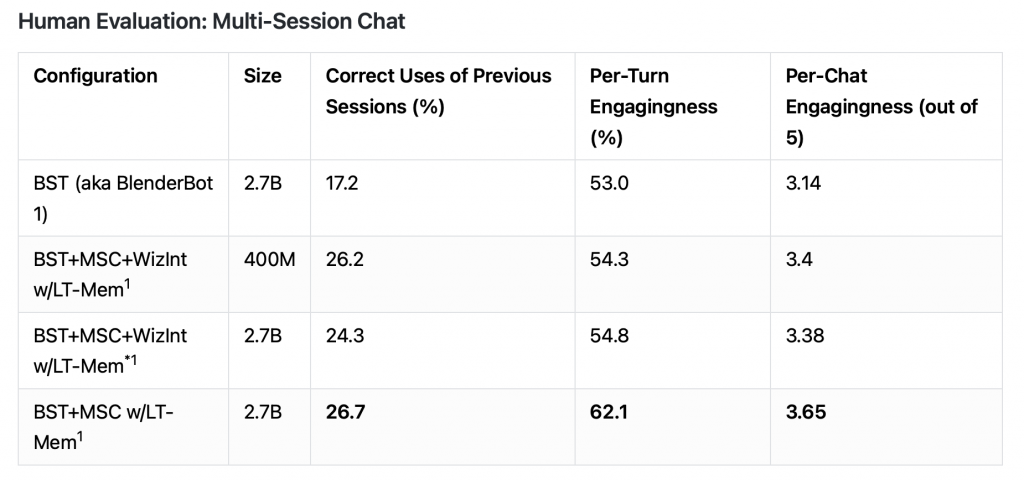
表2. 会話の中で知識を利用する性能(引用:https://parl.ai/projects/blenderbot2/)
4. おわりに
本稿では、AIを活用した対話システムについて、現在の動向と、最新モデルBlenderBot2.0について紹介しました。
現在の動向としては、
- 対話システムの研究開発が盛んに進められる中で、製品・サービスも徐々に普及してきています。
- 一方、現在の対話システムには、「正確な事実に基づくこと」「文脈的に矛盾がない会話を、長期間続けること」がまだ難しく、引き続き今後の研究課題となっていきます。
対話AIの最新モデルであるBlenderBot2.0としては、
- 長期記憶機能を持つことで、会話の長期的な文脈を考慮しながらの会話が可能になりました。
- 同時に、ネット検索機能を搭載したことで、世の中の最新情報をその都度取得し利用することで、より正確かつ詳細な事実に基づき発言できるようになりました。
今後も引き続き、対話(雑談)タスクを主軸に、自然言語処理に関するAIモデル・手法などについて、最新動向を追っていこうと考えています。
最後までお読みいただき、ありがとうございました。
著者プロフィール
名前:諸政利
株式会社オープンストリーム/サービスイノベーション統括本部
機械学習を活用した対話システムの開発に興味を持ち、学習を開始する。
自然言語処理全般に関心を持つ。
JDLA Deep Learning for ENGINEER 2021#1保有。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps