Keep Innovating! Blog

論文紹介: 異常検知において異常領域の可視化・異常判定精度の両方に優れた手法「Multiresolution Knowledge Distillation for Anomaly Detection」
目次
- ■はじめに
- ■異常領域の可視化:これまでの代表的な手法
- ■画像生成に基づく可視化(GAN, AutoEncoder など)
- ■パッチ分割に基づく可視化
- ■勾配情報に基づく可視化 (Grad-CAM の応用など)
- ■Multiresolution Knowledge Distillation for Anomaly Detection
- 1. 事前学習済みモデル(Source)を用意
- 2. 正常画像に対するSource の出力と同じ出力をするように別のモデル(Cloner)を学習
- 3. テスト画像に対する Source と Cloner のそれぞれ出力の差から異常度を算出して異常判定
- 4. 出力の勾配情報を用いて異常領域を可視化するためのヒートマップを算出
- ■実験による評価
- ■おわりに
■はじめに
技術創発推進室の中西です!ここ2年半ほど画像の異常検知の問題について考える日々が続いています。2年ほど取り組んで感じるのが、やはり異常検知の問題は通常の教師ありの問題と比べて難しいなということです。(もちろんどんな問題もそれぞれ難しいことは承知しておりますが...。)
特に画像の異常検知の問題で難しいと感じるのが、異常領域の可視化です。異常検知の問題に正常・異常の判定精度は当然求められますが、これに加えて「画像中のこの領域がこれぐらい異常である」ということを示す可視化の精度も求められることがあります。つまり画像に対して異常を視覚的に示すヒートマップのような結果が必要ということです。ユーザは判定結果だけではなく、目で見たときの納得感や説明性を求めている訳ですね。
さて、本記事ではそんな異常検知における異常領域の可視化についてまとめます。そして異常領域の可視化と異常判定精度を上手に両立させた最新の手法 「Multiresolution Knowledge Distillation for Anomaly Detection」を紹介します。
原文はarXivに投稿されており、URLは以下です。
https://arxiv.org/abs/2011.11108
この論文では、大規模データセットによる学習済みモデルに対して蒸留というテクニックを活用することで、オープンデータセットに対する実験において高い精度を示しています。
では、まず異常領域の可視化についてと、それを実現する手法について見ていきましょう。
※ 以降本記事で出てくる図は全て https://arxiv.org/abs/2011.11108 から引用しています。
■異常領域の可視化:これまでの代表的な手法
異常領域の可視化は以下のようなヒートマップ画像を出力することで行われることが一般的です。
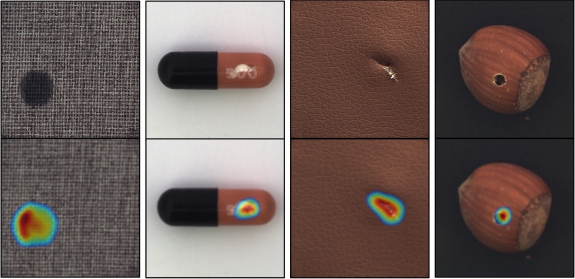
異常領域の可視化を行うために、これまで様々な研究が行われてきました。それぞれの研究で可視化の方法は様々ですが、本記事では代表的な3種類のアプローチを紹介します。
■画像生成に基づく可視化(GAN, AutoEncoder など)
画像生成に基づく可視化において、モデルは入力画像に近い正常画像を出力します。そして入力画像と出力画像の類似度や差分に基づいて異常判定を行います。例えば、正常画像を入力としたときは、入力に似た正常画像が出力されます。異常画像を入力としたときは、異常画像に似た正常画像が出力されます。これを踏まえ、入力画像と出力画像の類似度や差分を取ると、異常領域を浮かび上がらせることができます。従って、これをそのままヒートマップとして扱うことで異常領域を可視化することができます。
一方で差分や類似度を計算することによる性質上、画像や異常領域の特性によっては異常領域の可視化が困難です。例えば異常領域の画素値が正常領域の画素値と近い場合、異常領域の差分は小さくなってしまうため、可視化としては不十分な結果となってしまいます。
なお、画像生成に基づく手法については以前の記事(https://www.opst.co.jp/openinnovation/report/blog/report200713)で紹介しているので、興味がある方は読んでいただけると幸いです。
■パッチ分割に基づく可視化
パッチ分割に基づく可視化では手動で決定したサイズのパッチに入力画像を分割し、モデルはその各パッチの異常度を計算し、それに基づき異常判定を行います。そして各パッチの異常度を元の画像に対応する配置に並べなおすことでヒートマップの作成が可能となります。
入力画像をパッチに分割するため、パッチには異常検知を行いたい対象が写っていない領域が大きく含まれる可能性があります。例えば、異常検知したい物体に対して画像中に背景が大きく写り込んでいる場合を想定すると、パッチには背景領域のみが写っているものが含まれてしまうでしょう。そのため、モデルは物体以外についての特徴抽出も可能である方が都合が良い場合が多く、ImageNetのような大規模データセットによる事前学習を行ったモデルを活用する手法が提案されています。
この事前学習に基づく手法は近年着目されていますが、本アプローチにおいては適切なパッチサイズの決定が困難である、などの課題があります。
■勾配情報に基づく可視化 (Grad-CAM の応用など)
勾配情報に基づく可視化では、モデルが出力する正常・異常の分類結果に対して Grad-CAMと呼ばれるモデルの判断根拠の可視化の手法を適用することで異常領域の可視化をします。Grad-CAMは、モデルの説明可能性という枠組みで非常に注目されており、様々な発展型の手法が提案されています。
一方でGrad-CAMの特性上、細かいピクセル単位での可視化が困難であったり、可視化の結果の信頼性に問題がある場合があったりと、まだ課題はあります。
以上が、異常領域の可視化について、これまで提案されてきた代表的な手法でした。
■Multiresolution Knowledge Distillation for Anomaly Detection
本記事で紹介する「Multiresolution Knowledge Distillation for Anomaly Detection」では、前述の3つめの勾配情報を使った可視化に近い方法を用いて可視化を実現しています。ここからはこの手法の概要を説明していきます。
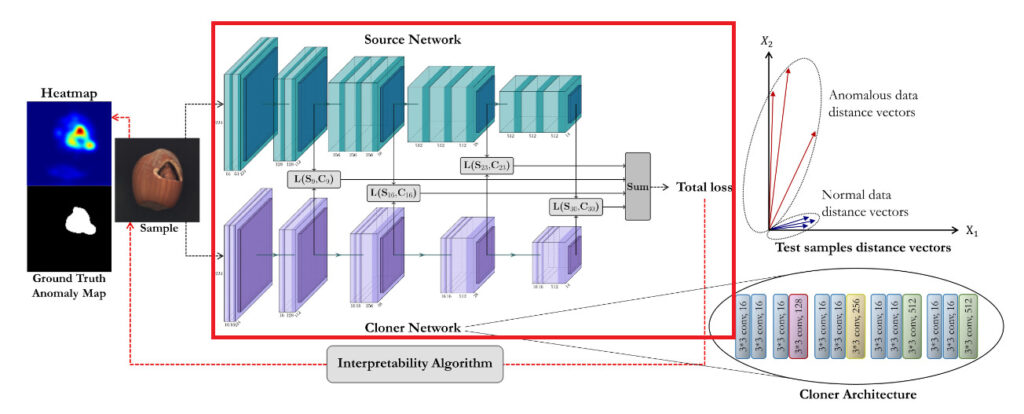
本手法における学習から推論までの大まかな手順は以下のようになっています。
- 事前学習済みモデル(Sourceとする)を用意
- 正常画像に対する Source の出力と同じ出力をするように別のモデル(Clonerとする)を学習
- テスト画像に対する Source と Cloner のそれぞれ出力の差から異常度を算出して異常判定
- 出力の勾配情報を用いて異常領域を可視化するためのヒートマップを算出
なお、モデルのアーキテクチャは以下の図のようになっていきます。
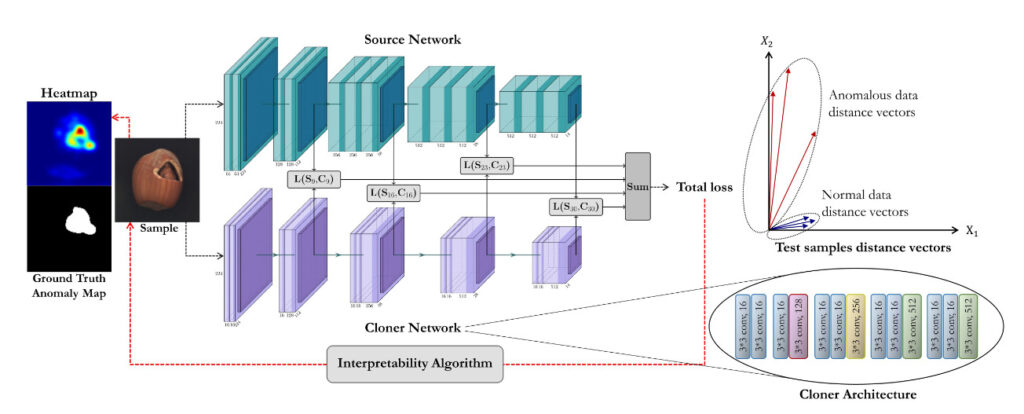
上記を踏まえ、ここからは図を確認しながら各手順について解説していきます。
1. 事前学習済みモデル(Source)を用意
まずは学習前の準備のフェーズです。本フェーズでは大規模データセットによって十分に学習されたモデルを用意します。後の手順で出てくる蒸留の考え方を踏まえてこのモデルを Source と呼びます。Source の構造は定められている必要はありませんが、画像を扱う問題に対して有効性が確認されている構造であることが望ましいです。論文中では ImageNet を用いて学習した VGG-16 が採用されていました。
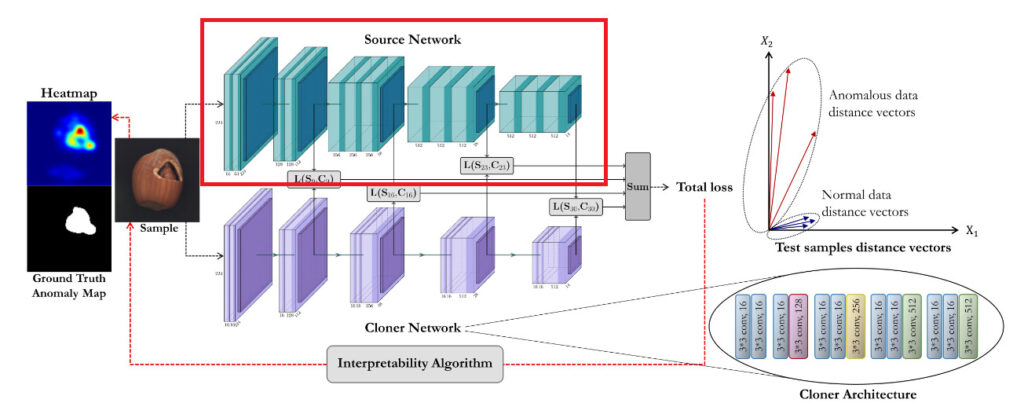
ここで Source が任意の画像に対してどのような振る舞いをするかについて確認しておきます。本論文では、Source は画像に関する情報を包括的に知っているモデルであるという仮定を置きます。つまり Source はどんな画像を入力されたとしても、何らかの意味のある特徴抽出が可能である、ということです。これは、大規模データセットを用いて良い構造のモデルを作っている、ということに根拠をおいています。この世に存在するあらゆる画像を使って、良い構造のモデルを学習させたら任意の画像の特徴を抽出することが出来るだろう、というモチベーションです。
これを踏まえ学習フェーズに入ります。
2. 正常画像に対するSource の出力と同じ出力をするように別のモデル(Cloner)を学習
学習フェーズでは 1. で用意したSourceの出力を真似るように別のモデルを学習します。このモデルはSourceと似た構造をとりますが、Sourceと比べて表現力が少ないものとします(例えば一部の層のチャンネル数を減らすなど)。
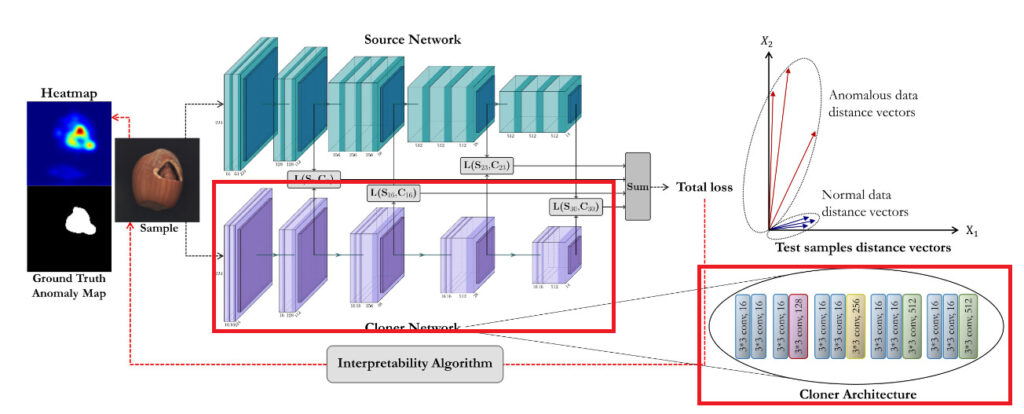
このように大きいモデルの出力を真似るように小さいモデルを学習させるというテクニックを「蒸留」と呼びます。そして Source の出力を真似して学習することから、本手法では学習する小さいモデルの方を Cloner と呼びます。この蒸留に用いる画像は正常なもののみを用います。これにより Cloner は 正常画像に対しては Source と似た出力をするようになります。
また、本手法においてはClonerの質を上げるために最終層の出力だけではなく、中間層の出力も真似るように学習しています。これは、本論文で引用されている先行研究においてニューラルネットワークの中間層の出力が入力画像の特徴を良く表現していることに根拠を置いています。その効果について興味がある方は、以下のURLから先行研究を確認してみてください。
( Fitnet: https://arxiv.org/abs/1412.6550 )
ここまでで学習フェーズはおしまいで、次節でいよいよ推論フェーズに入ります。
3. テスト画像に対する Source と Cloner のそれぞれ出力の差から異常度を算出して異常判定
推論フェーズでは、Source と Cloner の出力の違いを利用し、その差分に基づいて異常度を算出します。これについてもう少し深堀りするために Source と Cloner のそれぞれの出力について考えます。
まずテスト画像として正常画像を Source と Cloner それぞれに入力したとします。Sourceはあらゆる画像に対して良い特徴抽出が可能であるため、正常画像に応じた何らかの特徴が出力するはずです。また、Clonerは正常画像に対してはSourceと同様の出力をするように学習されているため、Cloner も Source と似た出力をするはずであると考えられます。
次にテスト画像として異常画像をそれぞれに入力したとします。正常画像を入力したときと同様に、Sourceは異常画像に応じた特徴の出力をします。一方で Cloner は異常画像は学習したことがないため、異常領域の特徴の出力ができません。このことから異常を含む画像をClonerに入力した場合、Sourceの出力と異なった出力が得られることが期待できます。
以下の図は特徴の差分ベクトルのイメージ図です。赤いベクトルは異常画像に対する差分、青いベクトルは正常画像に対する差分を示しています。本手法では、図のように差分の大きさの違いを見ることで正常と異常が判別できるだろう、と主張しています。
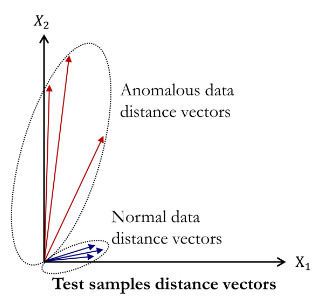
これらのことを踏まえ、SourceとClonerの中間層及び最終層の出力の差分を基に異常度を計算し、これに対して異常の閾値を設けることで異常検知が可能となります。
4. 出力の勾配情報を用いて異常領域を可視化するためのヒートマップを算出
最後に異常領域を可視化するためのヒートマップを計算します。これはとても単純で、以下の手順で計算します。
- 3. で計算した異常度を入力画素で微分する
- 得られた結果に対してガウシアンによるぼかしをかける
- モルフォロジー変換のオープニングの処理をかける
異常度に関して入力画素で微分をすると、各入力画素の異常度に対する影響の強さが計算できます。そこで本手法では、影響が強い画素が異常度を大きくしている原因であると解釈し、これをそのまま異常領域を示すヒートマップとします。ただし、そのまま使うとノイズが多く含まれてしまうため、それを除去するためにぼかしとモルフォロジー変換をかけます。そして、最終的に得られた結果をヒートマップとします。
■実験による評価
最後に、論文中で示されているオープンデータセットを用いた評価の結果について確認していきます。本記事では、MVTec AD のデータセット(https://www.mvtec.com/company/research/datasets/mvtec-ad/)を用いた結果をピックアップします。まずは画像上にヒートマップを重ねた結果から確認していきます。
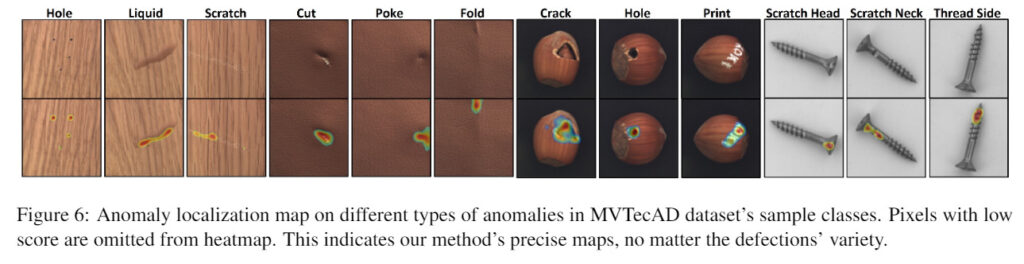
確かに様々な画像に対して良好な結果が得られているように見えます。異常領域の可視化は紹介したように様々な手法がありますが、テクスチャには強いがオブジェクトには弱い、もしくはその逆があったりと一長一短であることがほとんどです。一方で本手法ではテクスチャに対してもオブジェクトに対してもある程度良い結果が得られており、異常領域の可視化に優れていることが確認できます。次に異常判定の精度について確認していきます。
表1. AUROCによる精度評価の結果

表はMVTec ADの各データセットに対して異常検知の精度の指標であるAUROCを計算した結果です。AutoEncoderなど、異常検知における代表的な手法と比べてかなり良い精度が出ていることが確認できます。
■おわりに
本記事では、異常領域の可視化についてまとめ、それを実現する手法の一つ「Multiresolution Knowledge Distillation for Anomaly Detection」を紹介しました。
紹介した手法では、大規模データセットを用いて事前学習したモデルに対し、蒸留というテクニックを用いることで、精度及び異常領域の可視化に優れた手法が提案されていました。異常領域の可視化には様々な手法がありましたが、本手法では学習済みモデルを上手く用い、勾配情報を用いることで可視化を実現していました。
以前本ブログで紹介した学習済みEfficientNetを用いた手法( https://www.opst.co.jp/openinnovation/report/blog/blog-report201130_01 )の精度が良かったことも踏まえると、今後のトレンドとしては学習済みモデルを用いた異常検知が流行る可能性があるな、と感じました。また、ImageNetに代表されるデータセットの進歩は日々続けられていますし、モデルの構造も研究がかなり進んでいます。これらの知見を活用できるようなこのアプローチは非常に有用であると言えるのではないでしょうか。
本記事は以上となります、今後も最新の研究をキャッチアップして本ブログにて引き続き紹介していきたいと思います。
プロフィール
著者:中西正樹
株式会社オープンストリーム/技術創発推進室
大学院時代から画像処理の研究に携わっており、2018年から画像の機械学習の案件に参画。案件では最新の論文を読み漁り、フルスクラッチで実装することが多い。TensorFlowよりPyTorch派。
- テレワーク
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps